HIST4805a
Overall Plan for this Course
- this course is an EXPERIMENT. Who knows where it'll lead?
- who I am and why I'm interested in doing this experiment
- who are all of you?
PLAN, cont.,
- contextualize the emergence of large language models in terms of the historical and philosophical antecedents
- develop a critical perspective on the utility of these models
- situate their use in terms of the broader ethics of doing good history
- self-reflexive critical engagement with these technologies
The Imagined Flow in any given class:
- freewriting in your labnotebook re readings, previous classes
- discussion leaders
- break
- me waffling on
- hands on stuff maybe
TODAY'S TOPICS
- so, gpt eh? Used it?
- markov chains & a small language model made from matchboxes
- What the hell are these things models of?
- set up your lab notebook
- use obsidian OR
- use tangent note
goal: gift to future you; collaborative note space for the course; training corpus for our very own use-locally hist4805 AI
OK, Now On With The Show
Do humanists need to know how to code?
it depends. And bricolage & close reading can get you a long way
...and at any rate, Schmidt asked, do we need to understand algorithms?
It is good and useful for humanists to be able to push and prod at algorithmic black boxes when the underlying algorithms are inaccessible or overly complex. But when they are reduced to doing so, the first jo... should be to understand the goals and agendas of the transformations and systems that algorithms serve so that we can be creative users of new ideas, rather than users of tools the purposes of which we decline to know.
What follows would make a mathematician or computer scientist cringe.
That's ok.
The goal is digestible understanding for now that might lead you into deeper engagement later
How does language work?
Is it grammars? Is it structure?
A lot can be achieved through simple distributions of probabilities
But what probabilities?
Imagine:
coloured balls from a bag:
- take a ball out, throw it away, what's the p that the colour is red?
- take a ball out, look at it, put it back in, what's the p that the colour is red?
situation 1: probability changes over time situation 2: probability remains same over time

Andrey Markov
- Markov condition - future state is not dependent on history, only current situation
{kind=link}
This is a model of language. 'A' is a phrase. 'B' is a phrase. What is the probability that A transitions to B in two moves?
Move to B in two moves?
- A -> A -> B (0.3 x 0.7) +
- A -> B -> B (0.7 x 0.2)
- p = 0.35
Stay on A in two moves?
- A -> A -> A (0.3 x 0.3) +
- A -> B -> A (0.7 x 0.8)
- p = 0.65
Green Eggs and Ham as Source for a Language Model
{kind=link}
{kind=link}
Language can be modeled this way. A model might assume that the word 'cat' is always followed by the word 'walk' and it doesn't matter how many times you use the word cat, the highest probability next word will be 'walk'.
objection! If I'm not writing about theatres - with catwalks - or writing about how cats walk - a cat walk - I'd never write those two words together
objection! I'm a great writer, and if I use the phrase once, I'll use something different to describe a similar situation
Yes. Context matters. And that can be modeled through different mechanisms
{kind=link}
- Neural net - based on an imagined vision of how actual neurons work in the mind
- Training - change the weights until output matches desired outcome
- Backpropagation - technique to automatically figure out which weights to change to get closer to desired result
- sigma & f - the neuron. f the activation function
- Inputs add up to more than f? pass along an input to the next layer
Everything after this is elaboration and greater and greater complexity. Individual 'neurons' in eg a neural network trained on images might respond to edges, areas of flat colour, etc.
Ideas around Neural networks, markov chains, along with parallel computation and attention mechanisms, give us a large language models
- LLM: just a large file containing probabilities for words in its training corpus
- Text can be represented and transformed into an LLM
- Text embeddings are what are used today, rather than 'raw' text
A vector is a direction in space.
- 45.424721, -75.695000
- 41.90278, 12.49637
Add a third element, and we know something more about these two places
Word position in language can be expressed this way. Similar words occupy similar positions in word space
- bank (a place where money is stored)
- bank (the non-wet edge of a river)
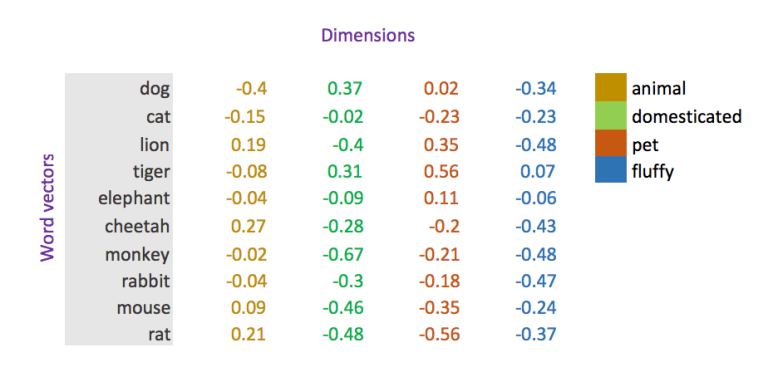
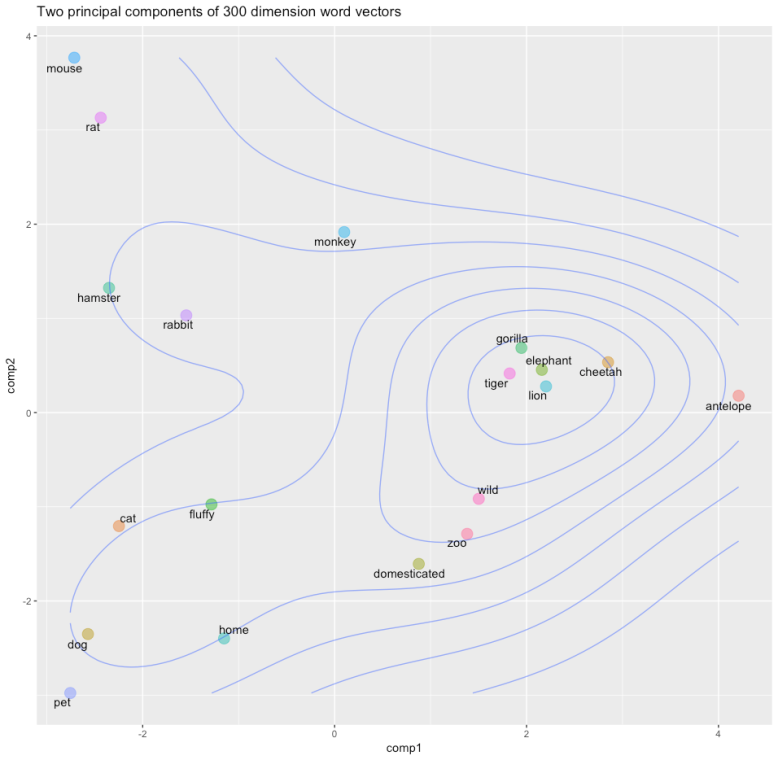
You can use neural networks to turn distributions of words into a large language model
You can fine tune the last few layers of a large language model with the patterns of word use in a corpus you're interested in, see Chantal Brousseau's tutorial
When LLM first came out, we interacted with them through completion ; it wasn't very popular
Slapping a chat-interface on top (which is what OpenAI did), and inserting several more layers of different kind of training between the 'foundation' model and the user interface (adding more human context through reinforcement learning where a human says 'good' or 'bad' in terms of the output produced through completion) leads to the current moment.
Gives us stochastic parrots
For next time:
- This piece is important, let's take a minute and look at it practice making notes about this in your labnotebook